What is recovery point objective (RPO)
Recovery point objective (RPO) describes a period of time in which an enterprise’s operations must be restored following a disruptive event, e.g., a cyberattack, natural disaster or communications failure.
It’s an important part of your disaster recovery plan, and is typically paired with recovery time objective (RTO)—the maximum time to restore critical functions following a disruptive event.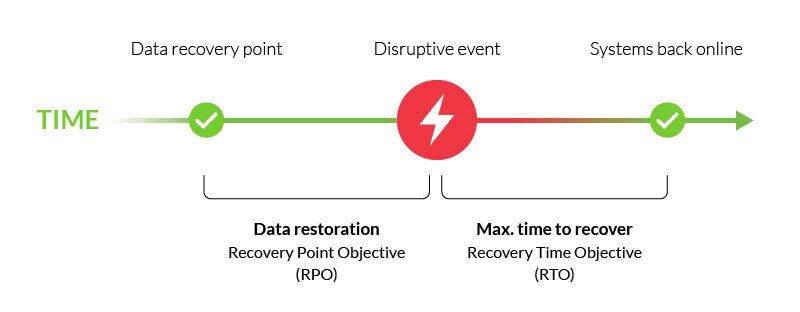
Each of your enterprise’s different processes, including communication networks and infrastructure should have unique RPOs, depending on their functions and importance. Here we will be covering how RPOs for data recovery should be defined according to your compliance needs and business goals.
Defining your RPOs
Typically, RPOs are set according to the frequency with which files are updated. This ensures that following a service interruption, your restored operations contain the most up to date version of your data.
For example, frequently updated files need a short (no longer than a few minutes) RPO. This means that following a disruptive event, operations can be restored with minimal data loss.
Factors that might influence your RPOs include:
- Industry – Enterprises dealing with highly dynamic or sensitive information (e.g., health records or financial transactions) update their files more frequently than those dealing with static files.
- Data storage – How your data is stored (e.g., in physical appliances, the cloud, etc.) can impact how quickly it can be retrieved following a service disruption.
- Compliance considerations – Numerous compliance schemes contain clauses dealing with disaster recovery and data availability. For example, SOC 2 certification requires a certain level of data availability and processing integrity, which can impact the acceptable amount of data that can be lost following a service disruption.
Once defined, RPOs should become the cornerstones of your business continuity plan, serving as goals for the processes it details.
In your plan, different RPOs should be set for various business units. For example, a mission critical data process, such as financial transactions, needs a shorter RPO than less frequently updated files, such as employee records.
Following are sample tiers you can use when setting the required RPOs for your business units:
0-1 hour
These are critical operations that can’t afford to lose more than an hour’s worth of data. Business and data transactions are usually higher in volume and more dynamic, making their recreation often impossible due to the number of variables involved.
Examples of this tier include banking transactions, your CRM system, and patient records.
1-4 hours
Business units that can afford data loss of up to four hours are semi-critical in nature. Examples include customer chat logs and file servers.
4-12 hours
Business units that fall within this category can’t tolerate losing more than 12 hours worth of information. Examples include marketing and sales data.
13-24 hours
The business units that comprise this category handle semi-important data, and require a RPO that goes back a maximum of 24 hours. This can include the human resources and purchase departments, which update data less frequently than outbound sectors of a business.
Failover and RPO
Failover is the process of switching between your primary and backup systems during a disruptive event or planned system downtime (e.g., routine maintenance).
When choosing a failover solution, it’s important to consider your organization’s RPOs to avoid losing an unacceptable amount of data when switching to a backup server.
For example, a ten-minute RPO means that your failover solution has to respond within that time frame to ensure you lose no more than ten minutes of data.
Failover methods include:
- DNS services – A DNS service routes traffic from a hardware solution to an off-site data center. This is useful for cross-data center recovery, in the event that an entire data center goes down. This process, however, has a number of potential downsides, including TTL related delays and service degradation, which could increase data recovery time.Additionally, the routing process could make failover uneven, as ISPs might continue routing traffic to the wrong server until their DNS cache is updated.
- Hardware solutions – Physical appliances are kept on-site. In the event that one goes down, traffic is automatically rerouted to a backup server.This solution has none of the latency issues associated with DNS failover. However, it requires the hosting of your backup site in the same physical location as your origin server. This is generally considered a bad practice, as it exposes the backup site to many of the threats that would impact your main server cluster (e.g., local power grid failure or natural disasters).
- On-edge services – Failover is managed off-site by a third party, where data can be seamlessly routed during a disruptive event. On-edge failover takes the best of both DNS and hardware-based solutions—there are no TTL related delays or additional costs associated with maintaining physical appliances. This ensures minimal data loss, allowing you to maintain your RPO goals.
Meeting your recovery point objective goals with Imperva
Imperva offers an on-edge service that provides security, performance and availability enhancing solutions for websites and web applications.
The failover feature we offer enables our customers to move their traffic to a backup site within seconds, be it a secondary on-premises server or a data center positioned on the other side of the world. This ensures continued functionality following a disruptive event, enabling you to set and maintain aggressive RPOs without having to worry about TTL related delays or appliance maintenance and security.
Our failover service comes augmented by other high availability features, including a high-capacity global CDN platform, comprehensive suite of DDoS mitigation solutions and an application-layer load balancer.