
What Is Data Anonymization
Data anonymization is the process of protecting private or sensitive information by erasing or encrypting identifiers that connect an individual to stored data. For example, you can run Personally Identifiable Information (PII) such as names, social security numbers, and addresses through a data anonymization process that retains the data but keeps the source anonymous.
However, even when you clear data of identifiers, attackers can use de-anonymization methods to retrace the data anonymization process. Since data usually passes through multiple sources—some available to the public—de-anonymization techniques can cross-reference the sources and reveal personal information.
The General Data Protection Regulation (GDPR) outlines a specific set of rules that protect user data and create transparency. While the GDPR is strict, it permits companies to collect anonymized data without consent, use it for any purpose, and store it for an indefinite time—as long as companies remove all identifiers from the data.
Data Anonymization Techniques
- Data masking—hiding data with altered values. You can create a mirror version of a database and apply modification techniques such as character shuffling, encryption, and word or character substitution. For example, you can replace a value character with a symbol such as “*” or “x”. Data masking makes reverse engineering or detection impossible.
- Pseudonymization—a data management and de-identification method that replaces private identifiers with fake identifiers or pseudonyms, for example replacing the identifier “John Smith” with “Mark Spencer”. Pseudonymization preserves statistical accuracy and data integrity, allowing the modified data to be used for training, development, testing, and analytics while protecting data privacy.
- Generalization—deliberately removes some of the data to make it less identifiable. Data can be modified into a set of ranges or a broad area with appropriate boundaries. You can remove the house number in an address, but make sure you don’t remove the road name. The purpose is to eliminate some of the identifiers while retaining a measure of data accuracy.
- Data swapping—also known as shuffling and permutation, a technique used to rearrange the dataset attribute values so they don’t correspond with the original records. Swapping attributes (columns) that contain identifiers values such as date of birth, for example, may have more impact on anonymization than membership type values.
- Data perturbation—modifies the original dataset slightly by applying techniques that round numbers and add random noise. The range of values needs to be in proportion to the perturbation. A small base may lead to weak anonymization while a large base can reduce the utility of the dataset. For example, you can use a base of 5 for rounding values like age or house number because it’s proportional to the original value. You can multiply a house number by 15 and the value may retain its credence. However, using higher bases like 15 can make the age values seem fake.
- Synthetic data—algorithmically manufactured information that has no connection to real events. Synthetic data is used to create artificial datasets instead of altering the original dataset or using it as is and risking privacy and security. The process involves creating statistical models based on patterns found in the original dataset. You can use standard deviations, medians, linear regression or other statistical techniques to generate the synthetic data.
Disadvantages of Data Anonymization
The GDPR stipulates that websites must obtain consent from users to collect personal information such as IP addresses, device ID, and cookies. Collecting anonymous data and deleting identifiers from the database limit your ability to derive value and insight from your data. For example, anonymized data cannot be used for marketing efforts, or to personalize the user experience.
How Imperva Helps Protect your Data
Imperva data security assists with data anonymization by masking data and classifying sensitive information. It provides multiple transformation techniques while ensuring enterprise-class scalability and performance.
Data anonymization and masking is a part of our holistic security solution which protects your data wherever it lives—on premises, in the cloud, and in hybrid environments. Data anonymization provides security and IT teams with full visibility into how the data is being accessed, used, and moved around the organization.
Before Anonymization:
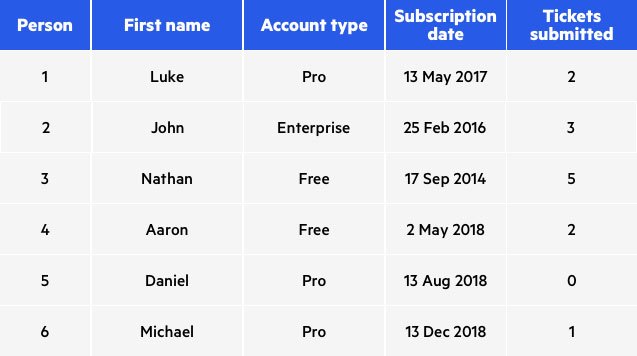
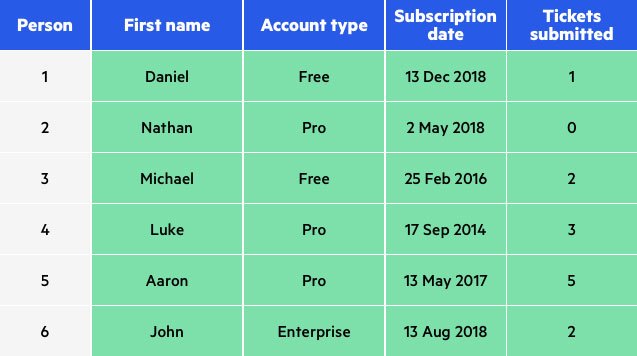
In this example, values for all attributes have been swapped:
Our comprehensive approach relies on multiple layers of protection, including:
- Database firewall—blocks SQL injection and other threats, while evaluating for known vulnerabilities.
- User rights management—monitors data access and activities of privileged users to identify excessive, inappropriate, and unused privileges.
- Data masking and encryption—obfuscate sensitive data so it would be useless to the bad actor, even if somehow extracted.
- Data loss prevention (DLP)—inspects data in motion, at rest on servers, in cloud storage, or on endpoint devices.
- User behavior analytics—establishes baselines of data access behavior, uses machine learning to detect and alert on abnormal and potentially risky activity.
- Data discovery and classification—reveals the location, volume, and context of data on-premises and in the cloud.
- Database activity monitoring—monitors relational databases, data warehouses, big data, and mainframes to generate real-time alerts on policy violations.
- Alert prioritization—Imperva uses AI and machine learning technology to look across the stream of security events and prioritize the ones that matter most.





