
What is business continuity
In an IT context, business continuity is the capability of your enterprise to stay online and deliver products and services during disruptive events, such as natural disasters, cyberattacks and communication failures.
The core of this concept is the business continuity plan — a defined strategy that includes every facet of your organization and details procedures for maintaining business availability.
Start with a business continuity plan
Business continuity management starts with planning how to maintain your critical functions (e.g., IT, sales and support) during and after a disruption.
A business continuity plan (BCP) should comprise the following element
1. Threat Analysis
The identification of potential disruptions, along with potential damage they can cause to affected resources. Examples include:
| Threat | Potential impact |
| Power outage | Inability to access servers |
| Natural disaster | Critical infrastructure damage |
| Illness | Widespread employee absences |
| Cyberattack | Data theft and network downtime |
| Vendor error | Inability to execute integrated business functions |
2. Role assignment
Every organization needs a well-defined chain of command and substitute plan to deal with absence of staff in a crisis scenario. Employees must be cross-trained on their responsibilities so as to be able to fill in for one another.
Internal departments (e.g., marketing, IT, human resources) should be broken down into teams based on their skills and responsibilities. Team leaders can then assign roles and duties to individuals according to your organization’s threat analysis.
3. Communications
A communications strategy details how information is disseminated immediately following and during a disruptive event, as well as after it has been resolved.
Your strategy should include:
- Methods of communication (e.g., phone, email, text messages)
- Established points of contact (e.g., managers, team leaders, human resources) responsible for communicating with employees
- Means of contacting employee family members, media, government regulators, etc.
4. Backups
From electrical power to communications and data, every critical business component must have an adequate backup plan that includes:
- Data backups to be stored in different locations. This prevents the destruction of both the original and backup copies at the same time. If necessary, offline copies should be kept as well.
- Backup power sources, such as generators and inverters that are provisioned to deal with power outages.
- Backup communications (e.g., mobile phones and text messaging to replace land lines) and backup services (e.g., cloud email services to replace on-premise servers).
Load balancing business continuity
Load balancing maintains business continuity by distributing incoming requests across multiple backend servers in your data center. This provides redundancy in the event of a server failure, ensuring continuous application uptime.
In contrast to the reactive measures used in failover and disaster recovery (described below) load balancing is a preventative measure. Health monitoring tracks server availability, ensuring accurate load distribution at all times—including during disruptive events.
Disaster recovery plan (DCP) – Your second line of defense
Even the most carefully thought out business continuity plan is never completely foolproof. Despite your best efforts, some disasters simply cannot be mitigated. A disaster recovery plan (DCP) is a second line of defense that enables you to bounce back from the worst disruptions with minimal damage.
As the name implies, a disaster recovery plan deals with the restoration of operations after a major disruption. It’s defined by two factors: RTO and RPO.
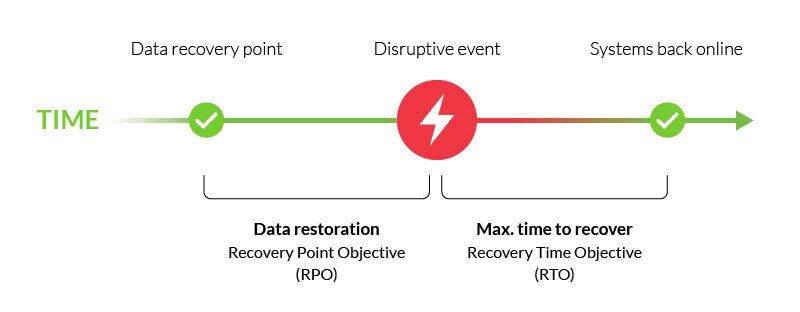
- Recovery time objective (RTO) – The acceptable downtime for critical functions and components, i.e., the maximum time it should take to restore services. A different RTO should be assigned to each of your business components according to their importance (e.g., ten minutes for network servers, an hour for phone systems).
- Recovery point objective (RPO) – The point to which your state of operations must be restored following a disruption. In relation to backup data, this is the oldest age and level of staleness it can have. For example, network servers updated hourly should have a maximum RPO of 59 minutes to avoid data loss.
Deciding on specific RTOs and RPOs helps clearly show the technical solutions needed to achieve your recovery goals. In most cases the decision is going to boil down to choosing the right failover solution.
Choosing the right failover solutions
Failover is the switching between primary and backup systems in the event of failure, outage or downtime. It’s the key component of your disaster recovery and business continuity plans.
A failover system should address both RTO and RPO goals by keeping backup infrastructure and data at the ready. Ideally, your failover solution should seamlessly kick in to insulate end users from any service degradation.
When choosing a solution, the two most important aspects to consider are its technological prowess and its service level agreement (SLA). The latter is often a reflection of the former.
For an IT organization charged with the business continuity of a website or web application, there are three failover options:
- Hardware solutions – A separate set of servers, set up and maintained internally, are kept on-premise to come online in the event of failure. However, note that keeping such servers at the same location makes them potentially susceptible to being taken down by the same disaster/disturbance.
- DNS services – DNS services are often used in conjunction with hardware solutions to redirect traffic to a backup server(s) at an external data center. A downside of this setup includes TTL-related delays that can prevent seamless disaster recovery. Additionally, managing both DNS and internal data center hardware failover solutions is time consuming and complicated.
- On-edge services – On-edge failover is a managed solution operating from off-prem (e.g., from the CDN layer). Such solutions are more affordable and, most importantly, have no TTL reliance, resulting in near-instant failover that allows you to meet the most aggressive RTO goals.





