
What is Data Obfuscation?
Data obfuscation is the process of replacing sensitive information with data that looks like real production information, making it useless to malicious actors. It is primarily used in test or development environments—developers and testers need realistic data to build and test software, but they do not need to see the real data.
There are three primary data obfuscation techniques:
- Masking out is a way to create different versions of the data with a similar structure. The data type does not change, only the value change. Data can be modified in a number of ways, for example shifting numbers or letters, replacing words, and switching partial data between records.
- Data encryption uses cryptographic methods, usually symmetric or private/pub key systems to codify the data, making it completely unusable until decrypted. Encryption is very secure, but when you encrypt your data, you cannot manipulate or analyze it.
- Data tokenization replaces certain data with meaningless values. However, authorized users can connect the token to the original data. Token data can be used in production environments, for example, to execute financial transactions without the need to transmit a credit card number to an external processor.
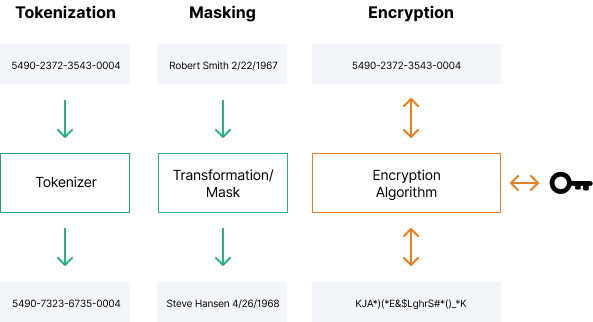
Three data obfuscation methods
Why is Data Obfuscation Important?
Here are a few of the key reasons organizations rely on data obfuscation methods:
- Third parties can’t be trusted—sending personal data, payment card information or health information to any third party is dangerous. There is a dual risk—it increases the number of people who have access to the data beyond the organization’s control, and it exposes the organization to violations of regulations and standards.
- Business operations may not need real data—any use of customer, employee, or user data is risky because it exposes the data to employees, contractors, and others. Many business processes, such as development, testing, analytics, and reporting, do not necessarily need to process real personal data. By obfuscating the data, the organization can maintain the business process but eliminate the risk.
- Compliance—many compliance standards require data to be obfuscated under certain conditions. For example, the European Union’s General Data Protection Regulation (GDPR) clearly stipulates the use of data masking for sensitive data collected about EU citizens.
What is Data Masking?
Data masking is the process of replacing real data with fake data, which is identical in structure and data type. For example, the phone number 212-648-3399 can be replaced with another valid, but fake, phone number, such as 567-499-3788.
There are two main types of data masking: static and dynamic.
Static Data Masking
Static data masking involves masking data in the original database and then copying it to a development or testing environment. This makes it safe to share the database with contractors or unauthorized employees.
Dynamic Data Masking
Dynamic data masking (DDM) is a more advanced technique that maintains two sets of data in the same database—the original, sensitive data, and a masked copy. By default, applications and users see the masked data, and the real copy of the data is only accessible to authorized roles. DDM is usually achieved by serving the data to unauthorized parties via reverse proxy.
What is Data Encryption?
Encryption involves scrambling data or plain text using an encryption algorithm, in such a way that it cannot be deciphered without the encryption key. Modern encryption algorithms are very secure and require infeasible amounts of computing power to crack.
There are two main types of encryption: symmetric, and asymmetric or public-key cryptography.
Symmetric Key Encryption
Symmetric key encryption encrypts and decrypts a message or file using the same key. It is much faster than asymmetric encryption, but the sender must exchange the encryption key with the receiver before decrypting.
Symmetric encryption requires users to distribute and securely manage a large number of keys, which is impractical and creates security concerns. This is why most modern encryption solutions are based on public-key cryptography.
Public Key Cryptography
Public key cryptography (also known as asymmetric encryption) uses two keys: a public key and a private key. The public key can be shared with anyone, while the private key is protected. A public-key encryption system uses an algorithm that requires a combination of the private and public key to unlock the message.
The RSA algorithm is a widely used public-key cryptography system. It is commonly used for digital signatures that can ensure the confidentiality, integrity, and authenticity of electronic communications.
Tokenization Definition
Tokenization replaces sensitive information with equivalent, non-confidential information. The replacement data is called a token.
Tokens can be generated in a number of ways:
- Using encryption, which can be reversed using a cryptographic key
- Using a hash function—a mathematical operation that is not reversible
- Using random numbers or index numbers
Once the original data is replaced with tokens—tokenized—the token becomes public information and the sensitive information represented by the token is securely stored in the “token vault”, a well-protected server. Only someone with access to the token vault can make the connection between the token and the original data it represents.
Other Data Obfuscation Techniques
Here are several other techniques your organization can use to obfuscate data in non-production environments:
- Non-deterministic randomization—replacing the real value with another, random value, within certain constraints that ensure the value is still valid. For example, ensuring the new value of a credit card expiration date is a valid month in the next five years.
- Shuffling—changing the order of digits in a number or code that does not have semantic meaning. For example, changing a phone number from 912-8876 to 876-7129.
- Blurring—adding variance to a number, while remaining in the general vicinity of the original number. For example, changing the amount of funds in a bank account to a random value within 10% of the original amount.
- Nulling—replacing original values with a symbol that represents a null character, for example, ####-####-####-9887 for a credit card number.
- Repeatable masking—replacing a value with another, random value, but ensuring that the original values are always mapped to the same replacement values. This maintains referential integrity.
- Substitution—replacing the original number with one value from a closed dictionary of values—for example, replacing a name with a name randomly selected from a list of 10,000 possible names.
- Custom rules—it is important to specify rules to retain the validity of special data formats, such as social security numbers, addresses, phone numbers, etc. For example, to perform obfuscation of addresses, you will need to use a geographical database and ensure you are replacing each element of the address with a valid value—street number, street name, city, country, etc.
A 4-Step Data Obfuscation Strategy
To succeed in a data obfuscation project, your organization should develop a holistic approach to planning, data management, and execution.
1. Data Discovery
The first step in a data obfuscation plan is to determine what data needs to be protected. Each company has specific security requirements, data complexity, internal policies and compliance requirements. The end result of this step is to identify classes of data, determine the risk of data breaches from each class, and the extent to which data obfuscation can reduce the risk.
2. Architecture
In the data discovery stage, the organization may classify data based on business classes, functional classes, or classes mandated by a compliance standard like PCI/DSS. A typical classification is into public, sensitive, and classified data.
For those classes that need to be protected by obfuscation, there is a need to carefully test how different types of obfuscation will impact the application. The business operation must be able to function normally under continuous obfuscation of the data.
3. Build
In this step, the organization builds a solution to perform obfuscation in practice and configures it according to the data classes and architecture that were previously defined. This includes:
- How to integrate the data obfuscation component with existing data stores and applications
- Preparation of datasets and storage infrastructure to store obfuscated versions of the data
- How to start the change management process.
- Defining obfuscation rules for different types of data
4. Testing and Deployment
Once the system is built, it should be carefully tested on all relevant data and applications, to ensure obfuscation is really secure and does not impact business operations. Testing involves creating one or more test datastores and attempting to obfuscate at least part of the production dataset.
As the project moves towards deployment, the organization must perform user acceptance testing (UAT), define organizational roles to take responsibility for obfuscation, and produce scripts that can automate obfuscation as part of routine business processes.
Imperva Data Security
Organizations that leverage data obfuscation to protect their sensitive data are in need of a holistic security solution. Even if data is masked, infrastructure and data sources like databases need to be protected from increasingly sophisticated attacks.
Imperva protects data stores to ensure compliance and preserve the agility and cost benefits you get from your cloud investments:
Cloud Data Security – Simplify securing your cloud databases to catch up and keep up with DevOps. Imperva’s solution enables cloud-managed services users to rapidly gain visibility and control of cloud data.
Database Security – Imperva delivers analytics, protection and response across your data assets, on-premise and in the cloud – giving you the risk visibility to prevent data breaches and avoid compliance incidents. Integrate with any database to gain instant visibility, implement universal policies, and speed time to value.
Data Risk Analysis – Automate the detection of non-compliant, risky, or malicious data access behavior across all of your databases enterprise-wide to accelerate remediation.





