


Everyone loves Artificial Intelligence (AI) and Data Science (DS), and it’s probably not going to change for the next decade or so. Even so, most people only have the general idea what data science is and what machine learning or AI algorithms can do.
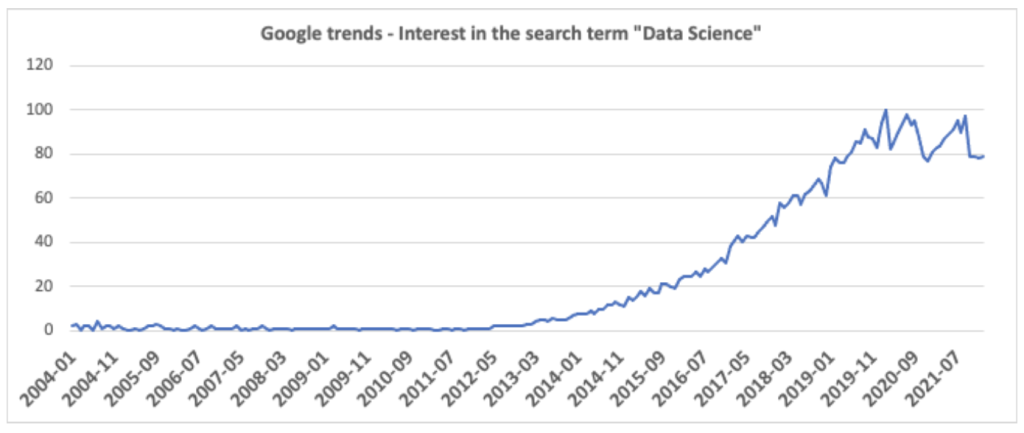
This is quite normal and a common phenomenon for every field of expertise. Think about it: do you really know what DevOps, Support, or NOC (Network Operation Center) actually do? Sure, as technology professionals we can probably explain it better than people who aren’t part of the industry, but in most cases it’s pretty difficult to truly grasp what other people do if you’ve never done it yourself.
In most cases this would be quite fine, because although gaining knowledge in other fields of expertise is always nice you can manage quite well without knowing everything. In fact, in most cases the additional knowledge might not even help you. That being said, Data Science is quite different from the other examples I just mentioned because data is everywhere. It’s easier than ever to store and manipulate data, and so Data Science and data-driven decision making is always relevant. Every department in every organization can benefit from data-driven decision making. DevOps can use Machine Learning (ML) algorithms to test their pipelines and detect anomalies, Support can use clustering algorithms to group similar customers’ requests and reduce their workload, and Network Operation Center (NOC) can use anomaly detection algorithms to detect malfunctioning networks. Since everyone can benefit from DS, we decided to find a way to help empower every willing employee with data science skills and spread some data science love.
Data Science Workshop Goals
We decided to create a workshop that would enable anyone with basic Python skills to quickly get a grasp of what DS is and to understand the “when, why, where, and how” it can be used.
We decided to set the following goals:
- Provide “Data Science Ambassadors” outside of our team with tools and a basic understanding of Data Science so we can work and collaborate with them
- Make the training brief and highly effective so “ambassadors” can do it while “on the job”
- Promote awareness of data-driven decision making and communicate the advantages of using it
We would achieve these goals with the following agenda:
- Explain ML and the basic algorithms
- Demonstrate how to spot machine-learnable problems
- Practice hands-on ML using Python and Sklearn
Our first thought was that there must be a DS course available online. And we did find many online courses, but none of them suited us for the following reasons:
- Very few courses cover as much material as we wanted to cover in a short time
- Most courses aren’t designed to be taught to a class, but are rather meant for people learning by themselves
- Math and Statistics weren’t a prerequisite for the workshop, so we needed theoretical explanations of ML models that could be understood by anyone
We came to the conclusion that we’d have to create the workshop ourselves.
Next, I’ll explain why we created our workshop agenda, and why it was so effective for teaching Data Science to newcomers in such a short time.
Explain ML and the basic algorithms
As the largest DS team at Imperva, we find ourselves getting involved with people from many different departments, such as Dev, Product, and Support, during our projects. One of the things we noticed was that people struggle with understanding how our ML solution fits into the projects and what it can actually do. At first we thought that because the ML solution was new, people had a hard time understanding how it fit into the project, but to our surprise, in future projects these issues didn’t repeat themselves and it became quite easy to explain how our ML solutions could fit into the project. We came to an understanding that people didn’t struggle specifically with our ML solution, they struggled with ML in general, and once they managed to get hold of the basics, everything got easier.
Demonstrate how to spot machine-learnable problems
In work, no matter our title or job description, we are surrounded by manual tasks. For the most part these tasks can’t be automated and definitely require human interaction. However, there are some tasks that seem like only a human can do, but a decent Data Scientist can probably create an ML model that can do the job.
Due to priorities, our DS team can only take on so many projects, and usually these projects revolve around the company’s core products. When we do find some time to work on peripheral projects, we don’t want to waste it sifting through the thousands of manual tasks going on in the company and figuring out which ones can be automated using ML.
Our solution was to train employees from other departments to be “Data Science Ambassadors”. These Ambassadors will have enough knowledge to spot problems that can be solved using ML, and then, depending on the problem’s complexity, either create a model themselves, create a model with our mentoring, or simply relay the problem to us to add to our backlog.
Practice hands-on ML using Python and Sklearn
Instead of just giving a high-level explanation, we wanted to get people to actually practice ML because we believe that hands-on practice is the best way to learn. Through this type of training, participants could not only understand ML and spot ML related problems, they could also start thinking about solving these problems themselves. It’ll also allow them to get a taste of DS and figure out if that’s something they would like to do more often.
How we did it
We split the workshop into four days, using three hours each day to make the workshop accessible to people while doing their job. We also made sure that each day had a different subject:
- Pre workshop – Installations of basic tools such as Python, Jupyter Notebooks and basic math, ML and visualization Python packages
- Day 1 – Overview of ML and basic Python packages (Numpy, Pandas, Seaborn)
- Day 2 – Supervised Learning – Linear & Logistic Regression, Decision Trees and Random Forest
- Day 3 – Unsupervised Learning – DBScan and K-Means
- Day 4 – EDL (Exploratory Data Analysis), Feature Engineering, evaluation metrics and final project
For the most effective delivery method, we used the following trinity:
- Presentations
- Code examples
- Exercises
Presentations
We used an online presentation tool for our slides because we wanted to share the slides and fix/edit them as we go along. We used the slides to explain ideas, concepts and algorithms without showing any code.
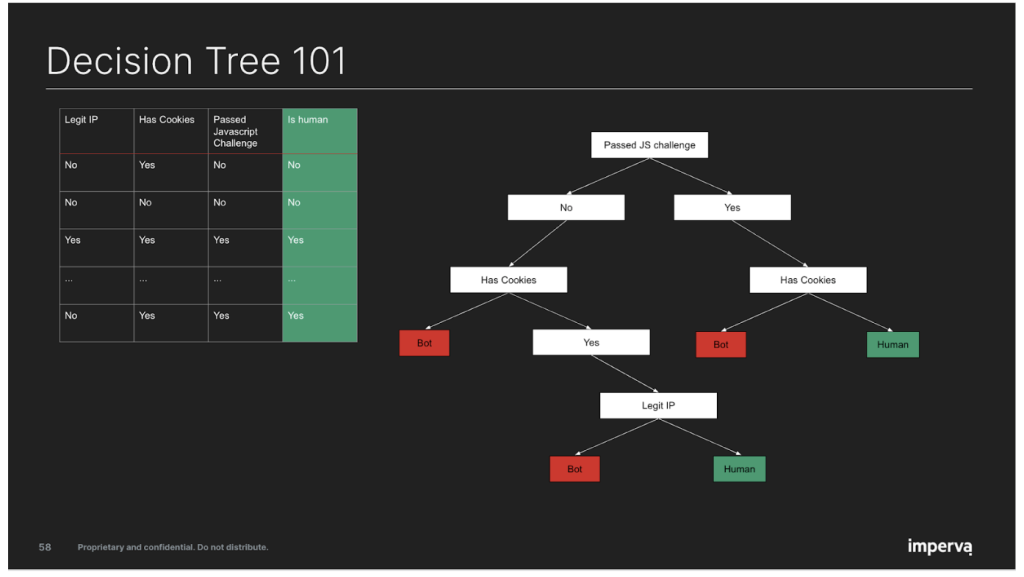
Code examples
We used Jupyter Notebooks to show live code examples. Each participant could clone the notebooks from our Git repository and run the code themselves. Not only did this help them understand the different commands, it was also something they could keep after the workshop ended. Furthermore, because notebooks are common practice for Data Scientists, simply using a notebook was training by itself, and it meant they had an environment set up for them if they wanted to further delve into DS.
Luckily the internet is loaded with example datasets we could use to demonstrate different concepts, methods, and algorithms.

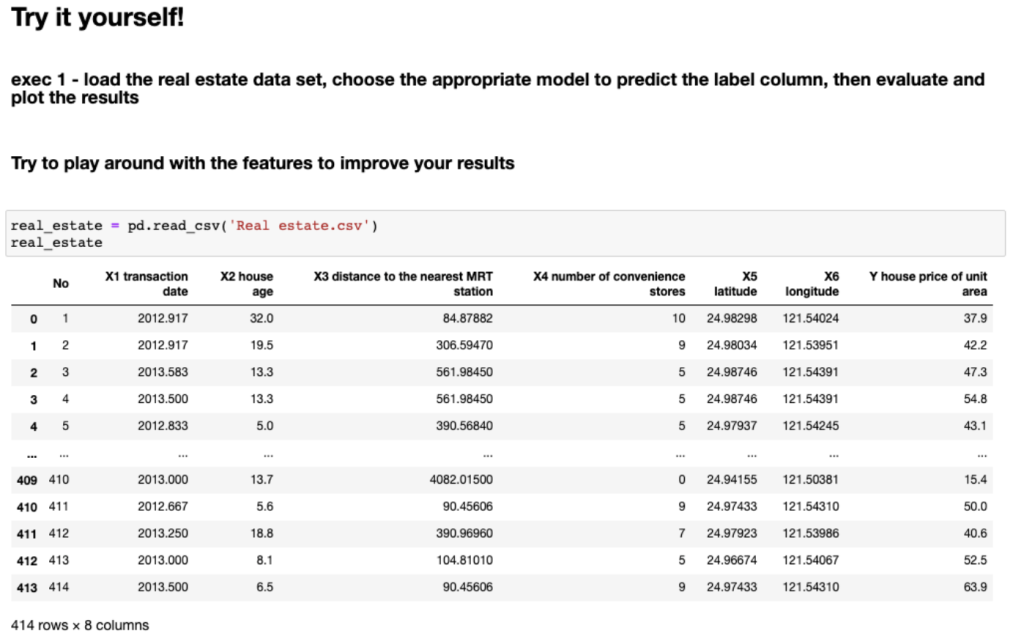
Exercises
For the exercises we used Jupyter Notebooks as well. This allowed us to start participants off with some basic commands for the exercise, such as loading the data, and letting them focus on the exercise itself. Also, because the code examples were in the same notebook as the exercise, it made it very easy to copy-paste the relevant commands required for each exercise.
Behind the scenes – final notes
Having a workshop with good content is nice, but you need more than good content to make it great!
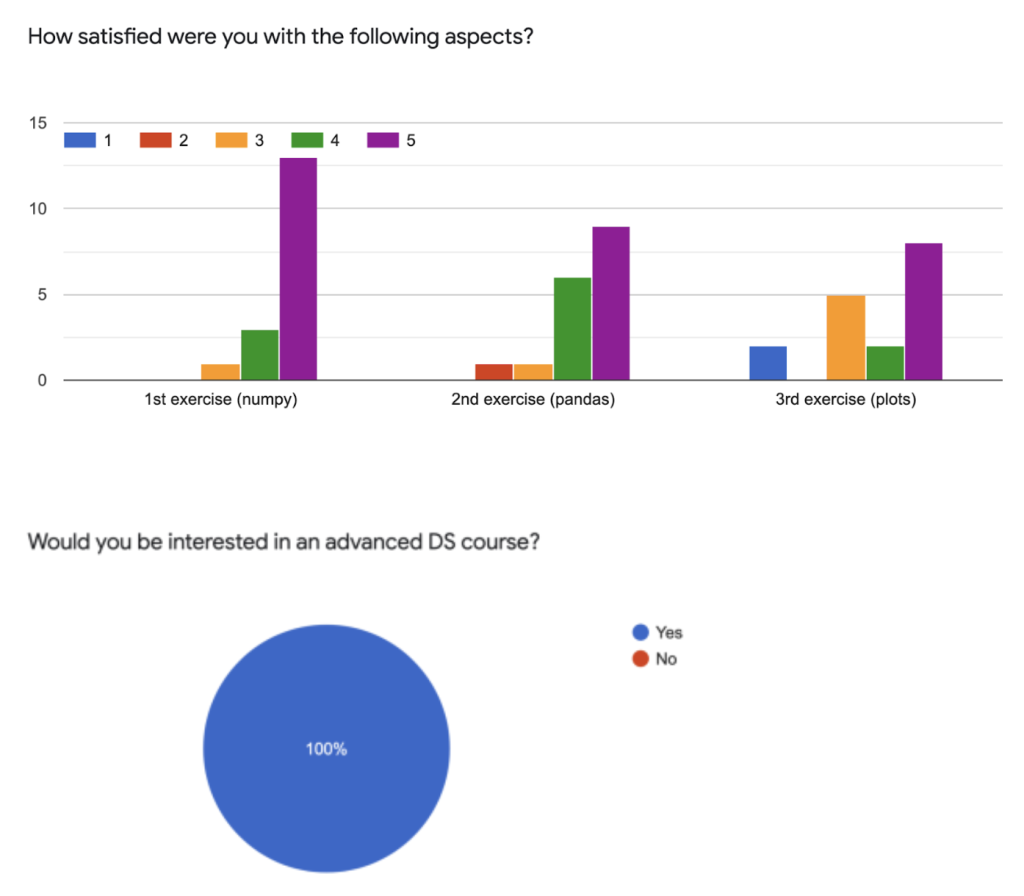
First and foremost – we sent a survey every day so we could get feedback about the previous day and improve the following day of the workshop. In the survey we used a 1-5 scale to get feedback on the following issues:
- Logistics – schedule, refreshments and breaks
- Content quality – how good were the exercises and slides
- Content relevance – how relevant was the content to the participants’ everyday work
- Overall feedback
Some examples of questions we asked in the survey:
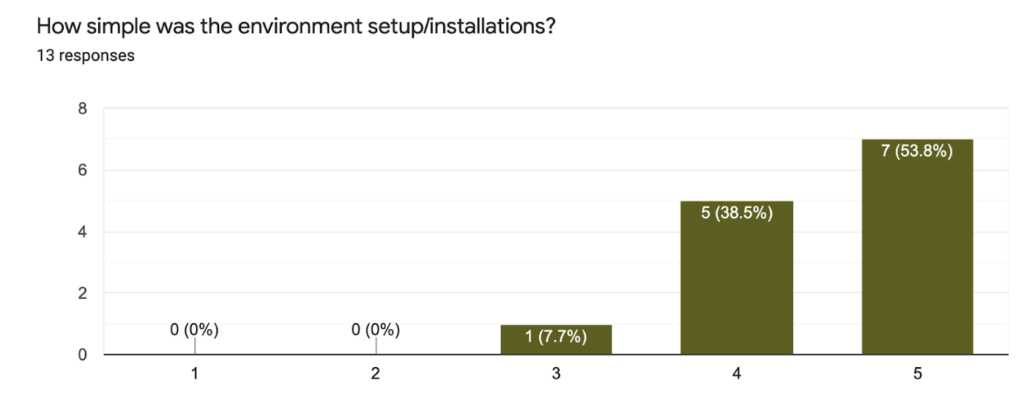
On top of that we made some additional efforts to make sure the workshop will run smoothly:
- Communications – we added everyone to a slack channel and a mailing list
- Refreshments – because the workshop is pretty intense, we wanted to make sure everyone would stay focused throughout each session, and so we ordered every day large trays filled with yummy refreshments such as sandwiches, fruits, veggies and sweets.
- SWAG – finally, in order to give the participants a sense of belonging, we gave out shirts tailor made for the workshop:

Try Imperva for Free
Protect your business for 30 days on Imperva.

