
![Machine Learning: Identify the Unpredictable – Whiteboard Wednesday [Video]](/wp-content/themes/impv-blog/dist/imgs/default-thumbnail/data-security.jpg)

When it comes to identifying insider threats, the fundamental challenge is how to determine when data access appears out of the ordinary for a typical user or system, and of those instances, which ones are dangerous versus merely unusual.
A lot of solutions today serve up so many policy violation alerts, or potential violation alerts, that it’s nearly impossible to find the real red flags that indicate you’ve got a problem.
Enter machine learning. It offers the ability to analyze and crunch data at a scale that’s simply impossible for humans. But without domain expertise on the problem it’s trying to solve it can fall short on its promise to deliver value.
In this month’s Whiteboard Wednesday, Imperva CTO Terry Ray talks about machine learning and how a deep understanding of databases – user types, data types and database types – allows Imperva to go beyond traditional policy settings to accurately identify unpredictable data access and prevent breaches.
Machine Learning: Identify the Unpredictable – Video Transcription
Hi, welcome to Whiteboard Wednesdays. My name is Terry Ray, I’m the Chief Technology Officer here at Imperva. Today we’re going to talk about machine learning, and really, how to identify the unpredictable.
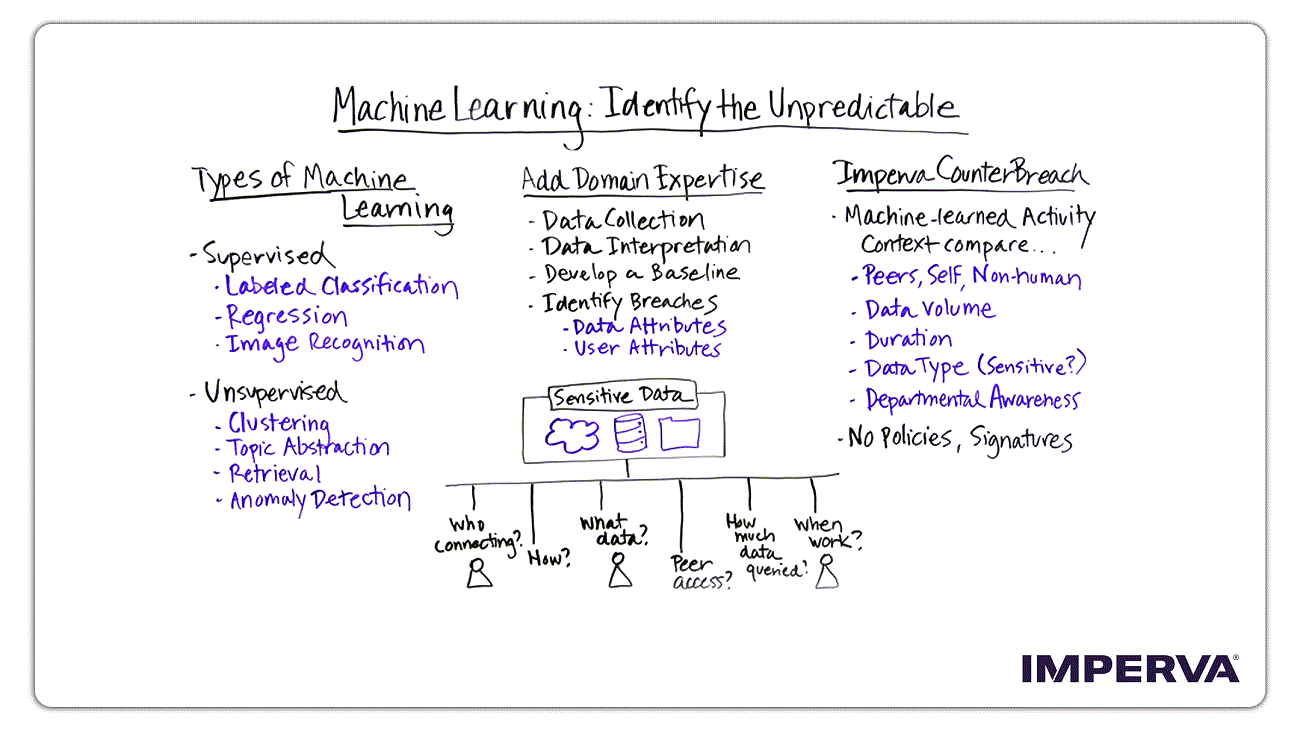
Types of Machine Learning
When we think about machine learning we really think about two things generally: supervised machine learning and unsupervised machine learning.
Supervised Machine Learning
Image recognition. When we think about supervised, it’s one of the things that we see a lot of people talk about when we’re talking about these things. When we think about image recognition, you’ve seen it on TV where people will say, “I need to track this person,” and you see all the video screens and they’re looking for a very specific face. They know what it looks like and that’s what they’re looking for all around the world in CCTV or wherever it is.
Labeled classification. It’s where you might be looking for a certain type of fruit. You know what that type of fruit is, you know what it looks like and you’re trying to identify it in a grocery store. You’re finding apples anywhere in the grocery store, for example. That would be supervised learning. You’re giving some input, so the supervised learning can understand when it’s right or when it’s wrong.
Where we tend to sit and where a lot of organizations have moved today with regard to machine learning, is a little bit closer to what many people think of as artificial intelligence. Now artificial intelligence for most people is The Terminator or other sorts of things where we’re talking about these machines that mimic humans. That’s not what we’re talking about here. We’re talking about just moving a little bit closer to where the machine does a little bit more for you, than what it has in the past.
Unsupervised Machine Learning
Unsupervised machine learning is what we do at Imperva. It’s what many other organizations are doing today and it leverages several other types of features or technologies. I’m going to start from the bottom.
Anomaly detection. When we think of anomaly detection, we’re thinking, for example, of a heartbeat monitor monitoring your heart for irregularities, for irregular heartbeats.
Retrieval. Many of us use this. Things like Facebook and Google and maybe even Watson AI or QA, where you ask a question and it goes out and finds all the relevant answers that are most appropriate to what you’re asking.
Topic abstraction. When we think of topic abstraction, we’re thinking about well, what are people talking about today? Whether it be Twitter or Instagram or what have you, what’s the most common things that people are talking about? What’s relevant to me based on what I like.
Where we sit at Imperva is we use clustering technology. We use a few underlying technologies that we won’t go into today just by virtue of time. When we think of clustering, clustering allows us to gather lots of different information together that individually you wouldn’t really know or find much value in, but as we start to cluster this information together we bring other data and our knowledge together with that which really makes it something that is usable and contextual that we can use in an environment.
Domain Expertise
When we think about supervised and unsupervised, Imperva is leveraging unsupervised technology in machine learning with clustering. Now there’s algorithms that we use in there as well that we won’t go to the detail here, but the real value and difference is when Imperva starts working toward machine learning, we’re talking about bringing our domain expertise. Domain expertise is the ability to take what we’ve learned over years and years of working with databases and files and applications, bring it to bear on a large set of data, so much data in fact, really a human can’t look at it anyway. We understand that in most cases, most humans don’t even see more than about 5% of the overall alerts, much less the raw data that generated those alerts.
Data collection
When we think about one of the key aspects to machine learning, it’s data collection. How much data can you actually collect? If you can’t collect a large volume of data that covers the breadth of all of your users and all of your applications and all of your data access and the different types of data, your machine learning’s going to suffer. The value and the accuracy of your machine learning’s going to suffer. Data collection is critical, but that’s not the only thing. Not only do you need the technology to collect the data, but you need the technology to be able to interpret that data.
Data interpretation
Now, Imperva’s been doing data interpretation in the database and the file server, and the application side for that matter, for 14-15 years at this point. What does that mean for interpretation though? Think about a SQL query. In a SQL query we have a user. Lots of applications can understand users. Source IP, destination IP, maybe even an application, lots of tools that do machine learning can understand that.
The real key when we think about data, take databases for example, what about the query? Select star from table name, where the table name is something. What does that mean to anybody and how many different ways can I write that to mean the exact same thing. Think about Oracle, MS SQL, Sybase, DB2, big data. All these other platforms that you happen to have, they all speak different languages. That’s the challenge when we think about the data realm, unlike, say, an FTP server, or an F Telnet server, they’re all using the same protocol all speaking the same language.
When we think about the database space, they all speak different languages, which means we have to interpret that data, so that we can build a model upon that data and then make that model effective. That’s what we’ve done over about 14 to 15 years and that’s why we speak about 30 different database languages and file languages that allow us to be able to interpret this data. These two are absolutely critical in getting anywhere.
Develop a baseline
From there we start to develop a baseline. That baseline is, what is the normal behavior? What does it look like when we understand what normal traffic looks like? Is it a human touching a table? Is it an application touching a table? How do these people really interact with that environment? When we build the baseline, it now allows us to look at anomalies to the baseline. Anomalies to the baseline are the ability to identify breaches. Tell us when something’s going awry, when something’s not right.
We look at two different areas. Rather than looking at just users or rather than looking at just data, we combine those two together and say, “Look, I understand that this is a human user and this human user is touching table data that only the application ever touches.” That’s not a prescriptive policy that I wrote that said, “Only that application should touch that data.” I would have to predict that to do that. Instead, through analytics I know that only the application has ever touched that data. While they’re might be some users that touch the data rarely, maybe this particular user never touches that data or maybe they only touch it rarely. When they do, they touch it with a very specific user account, not a system user account.
Being able to determine how somebody’s interacting with the data, when they interact with it, and why they interact with it is a critical piece. Again, it all builds upon the capacity to start at the beginning and work your way through using machine learning to do the bulk of the work, but adding in Imperva’s domain expertise to be able to answer questions that, frankly, you should be able to answer, but the human effort in answering these question is tremendous if you don’t have machine learning to help you out.
Identifying sensitive data
Who’s connecting to the data? How do they connect to it? What data did they touch? What do their peers do? Do they access it the same way that this person does? How much data did they touch? Too much? Too little? When do they work? These are all questions that should be able to be answered, but if you don’t have this kind of capacity, this type of technology, you just can’t answer these questions. It’s just too much manual work.
Imperva CounterBreach
If I look over here from a CounterBreach perspective, when we think about Imperva and its machine learning, we call it CounterBreach. CounterBreach is the technology that allows us to do all these things we’ve talked about, but what sets it apart? One of the common questions is, “How is this different from what Imperva’s been doing all along?” Well, for years Imperva has been doing what’s called database activity monitoring and file activity monitoring. It allows us to monitor the activity of files and databases, but what’s different here is in the past we had to be more prescriptive. We had to predict what people were going to do in your database, in your file server. I had to write a policy that said, “This user should touch this data and these two users should touch that data, but this user should never touch any of that data,” and I had to know that because I had to understand how people interacted with my data myself or my team.
Contextual Comparative Analysis
But who knows all that about all of your databases and all of your file servers? The answer is nobody, so automation allows us to use CounterBreach to do that for you. CounterBreach uses machine learning to use a contextual comparative analysis, allowing us to look at, “How do I compare myself to my peers? How do I compare what I did today from what I did yesterday? How do I compare myself to an application that’s touching the data? Am I different? Am I the same? Am I touching data that only it touched or is maybe my application compromised and it’s touching data that only I touch? How much data am I touching? Yesterday, I touched five files. Today, I touched 5,000 files.”
The technology that allows us to see this is immense in that I have to look at every single user and every user over time to know what they did yesterday, so I can understand what they did today and I have to see it all. The duration, of course, how long they do it, when they operate, what time they come to work. The data type, is it sensitive? Is it not? That’s obviously going to up the scale of how important things are is the sensitivity.
Departmental awareness…do I have somebody in engineering touching a mergers and acquisition’s department file? Should they be touching that file? I can tell you whether they should or whether they ever have before because I have that history and that context.
Capacity to Understand How People Interact with Data
The reality is, and the final piece is it gives you the capacity to understand how people touch your data, when they touch it, why they touch it, should they be touching it, but it does not require you to be a data security expert. It doesn’t require you to be a database expert or a file expert or speak any of the database or file languages that we speak. We do all of that for you. That’s the value of introducing and injecting automation into a process allowing us to understand and predict, frankly, the unpredictable.
Thank you for joining us on Whiteboard Wednesdays. I hope to have you back next time. Thank you.
Try Imperva for Free
Protect your business for 30 days on Imperva.





