

Configurable systems have a high level of flexibility and are better adapted to most customer needs, but their management isn’t a trivial task in complex cloud deployments.
The configuration management concept isn’t new and originated in the United States Department of Defense in the 1950s as a technical management discipline for hardware material items. In a software environment, it has a different meaning, but the concept remains the same.
Let’s take a closer look at why it’s so important in our system and how we handle it.
The Dilemma
Administrators, support engineers or any other people who deal with services or products, like configuration. Product or service parameterization allows adjustment to customer needs exactly as the customer requires. This can be done by a small modification of default configuration or by enabling/disabling a feature. Of course, the default settings should be simple and meet the need in most cases, but they do not fit all of them.
As developers we hate configuration, it makes for messy code. Configuration creates complexity, and any parameter in it or its change adds additional testing. Since developers don’t rule the world, however, we need to make do. On the other hand, we are responsible for providing a stable and reliable service, so how do we find a happy medium?
The simple answer to that would be “more unit-testing” or “more testing” to account for all possible scenarios, right? Well, some managers would agree, but the real world is a little bit more complicated than a Q/A lab. Our R&D and test automation teams are already doing a great job, but it’s not always enough since there are practically infinite combinations of configurations, and testing alone cannot mitigate the risk.
We know that configuration validation should be done in a real-time environment, so the Imperva Incapsula engineering team created a few mechanisms for self-protection. These mechanisms ensure close to zero impact for our customers in production, by checking correctness and fast recovery in the face of errors.
In this post, we’ll describe a few of those mechanisms, some basic, like schema validation, others more complicated, like configuration snapshot management.
Let’s kick it off with a simple configuration flow.
Configuration Flow
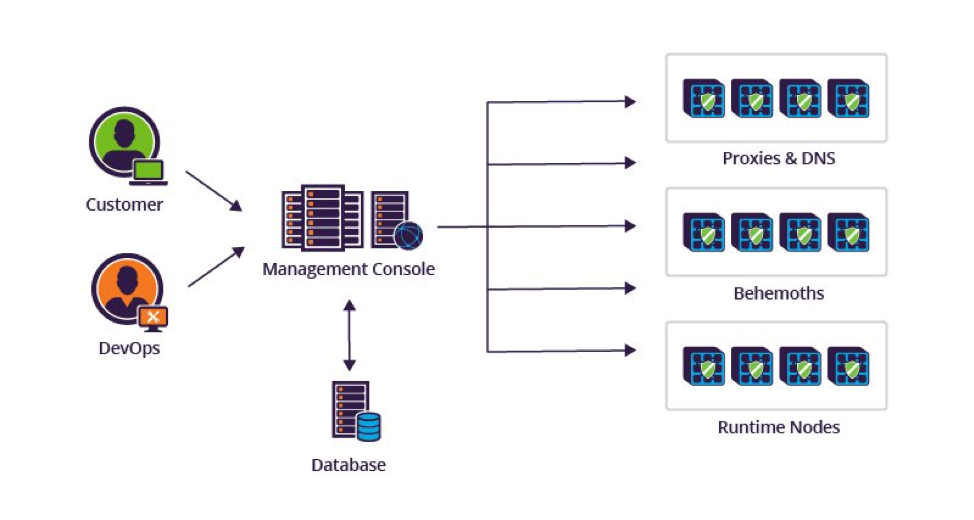
Customer configuration is transferred from one agent to another by employing what we refer to as a “shield”. In each case, every agent ensures the configuration is correct. We do this to achieve two goals:
- Catch the problem as fast as possible, because early detection is crucial for a timely resolution
- Some shields have overlapping protection for better detection
Let’s take a closer look at these shields. Every configuration asset is protected by several shields as described in the following illustration but not necessarily by all of them. Each shield is described below.

Management Console Configuration Shield
The Imperva Incapsula Management Console is used by both customers and operations staff. Its job is to receive configuration changes via the user interface or API, store it in the configuration database and notify the next agent that a configuration change has occurred.
The Management Console performs the following validations:
- Schema correctness – configuration structure is correct for both database storage and runtime components. For example, data types validation.
- Semantic correctness – any changed or added configuration is validated under its scope. For example, model state changes.
- Data relationships – data should be correct relative to another component in the system. For example, customer site name or GRE tunnel IPs.
Once the problem is detected, the user is immediately notified and the configuration update is rejected.
Configuration Sandbox Shield
In addition to performing static validations, Imperva Incapsula also sandboxes configuration changes in a live system before propagating it to the production network. The goal of this step is to detect unexpected issues with the configuration.
The configuration is loaded into fully operational runtime nodes, which try to detect the problem, anomaly or incorrect behavior. Note that the runtime nodes do not serve customer traffic. In the unlikely event that a configuration error is detected, the configuration change is isolated and will not affect customer traffic.

As described in illustration, at this point, valid configuration changes reach production nodes and affect customer traffic. However, issues that result originate from unexpected traffic patterns can still show up. So, an additional shield is required to ensure that such issues are handled gracefully.
Runtime Node Configuration Shield
Runtime nodes implement the last protection point which allows them to recover from bad configuration changes, even ones that cause the process to abruptly terminate (crash). The mechanism keeps a Last Known Good (LKG) snapshot of the configuration repository and is able to revert to it when needed. As opposed to previous shields, this one operates at the repository level. We chose that design because it might be very complicated to discover a single bad configuration change and we want to recover as quick as possible.
This shield’s implementation covers the following stages:
- Background – the system maintains snapshots of LKG repositories
- Detection – the system detects issues with the repository
- Decision – the system decides whether a repository is safe to use or not
- Rollback – the system reverts to an LKG repository
- Recovery – once the configuration is fixed, the system recovers to the most recent version of the repository
This shield is our last line of defense, and we do not expect it to take action on a daily basis. However, if that occurs, our monitoring systems notify the relevant teams to immediately investigate and find the root cause of the issue, as described in our post: How to Tame “Monitorture” and Build a Developer-Friendly Monitoring Environment.
Runtime Node Configuration Shield Implementation
In this last section, I’d like to share some details about how we implemented the runtime node configuration shield.
We keep the configuration in files, so we wanted to find a solution at the file-system level. We evaluated several options for file-system snapshot management and decided to go with Btrfs storage, which is based on the copy-on-write (COW) principle. Btrfs has built-in snapshot functionality and meets our performance requirements.
Over Btrfs, we implemented a small open-source component, which is run as a service and creates snapshots for different repositories defined in our system. This component is generic and can be used by any product to achieve the same goal.
The following configuration is an example of possible repositories:

Configuration example of this service[/caption]
Repository represents the Btrfs device managed by snapper, while snapshot_level represents snapshot frequency and links to the latest snapshot taken under this snapshot level. Each repository can define several snapshot levels based on business logic or frequency of configuration changes.
The snapper creates a snapshot periodically based on configuration but stops if any defined “stoppers” exists.
Runtime components use master configuration until the configuration problem is detected. Once detected, the component tries to load the latest good snapshot configuration with links defined in the configuration. In addition, the stopper should be created or ordered to stop snapper functionality.
We believe that similar techniques can be used in any cloud service. These mechanisms help us provide a reliable service and we strive for a reality in which they will not be activated. But if they are, our customers can rest easy.
Try Imperva for Free
Protect your business for 30 days on Imperva.

