
![Challenges of Insider Threat Detection – Whiteboard Wednesday [Video]](/wp-content/themes/impv-blog/dist/imgs/default-thumbnail/data-security.jpg)

Insider threat detection and containment of insider threats requires an expert understanding of both users and how they use and access enterprise data.
In our first Whiteboard Wednesday, Drew Schuil, Vice President of Global Product Strategy at Imperva, talks about the challenges of insider threat detection and approaches to protect sensitive data and large repositories of data from careless, compromised, and malicious users.
Video Transcription
Welcome to Whiteboard Wednesday. My name is Drew Schuil, Vice President of Global Product Strategy with Imperva. Today’s topic is Challenges of Detecting Insider Threats, particularly when we’re talking about sensitive data and large repositories of data, like databases, big data systems, and file repositories.
Click to enlarge image.
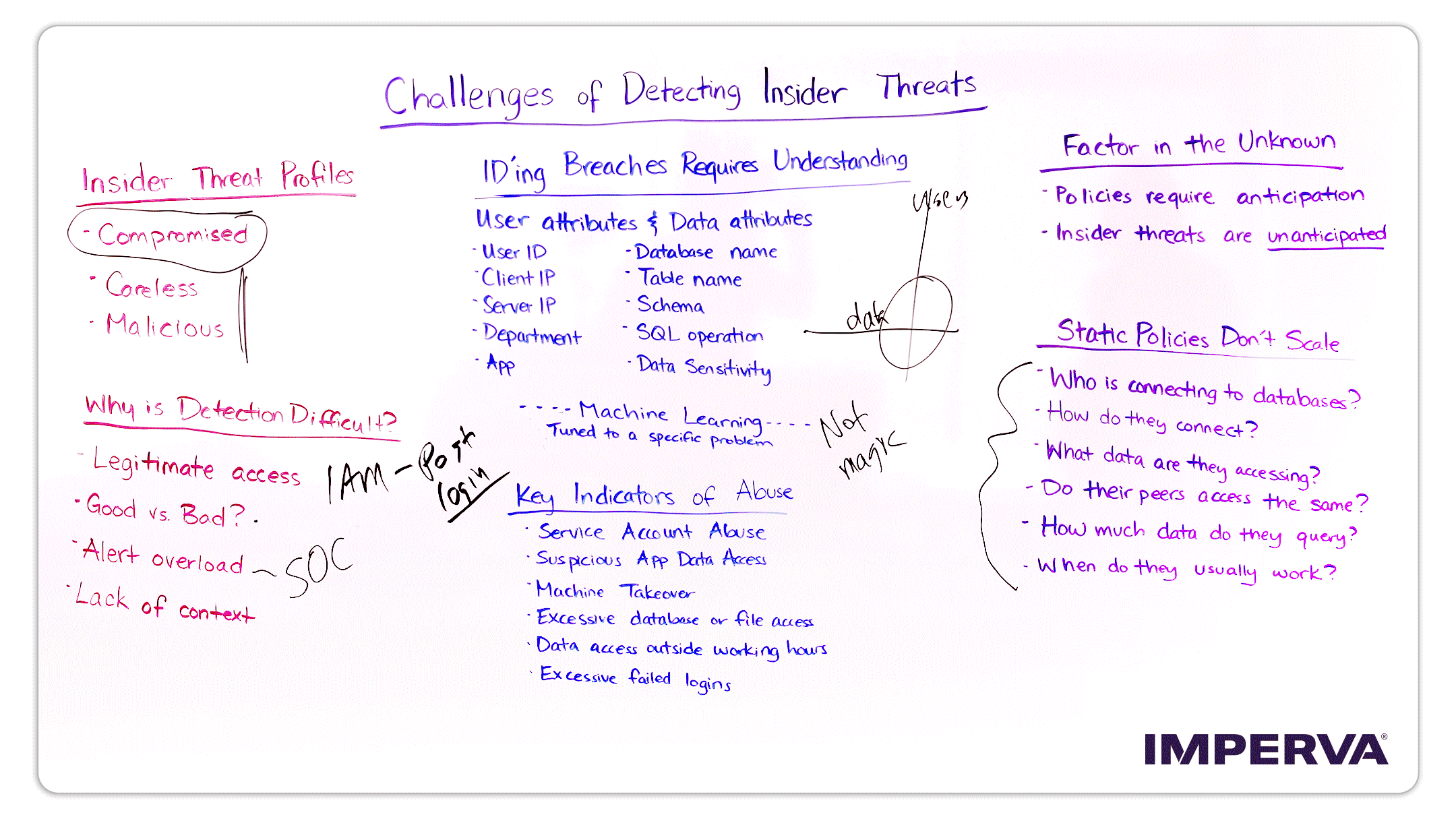
Insider Threat Profiles
We’re going to start off with insider threat profiles. I’ve got three already [on the board], compromised, careless, and malicious.
- Let’s look at compromised. This is where most of the security industry is focused. When we think about compromised users, think about users that have clicked on a phishing link, users that have gotten their endpoint infected somehow through malware, and now the attacker is inside the network. They’re perhaps moving laterally through the organization, doing reconnaissance, trying to find where sensitive data is and compromise additional credentials to get access to it. If you look at the security solutions that organizations are implementing today—endpoint security, sand boxing, anti-phishing—a lot of the security solutions are really designed to look for this use case and try to stop it as soon as possible, to quarantine the compromised user.
- Two more, I should say, overlooked user profiles, are careless or negligent users. Think of a DBA who’s got legitimate access to the network but is using short cuts to get a job done. Maybe they don’t want to go through the change control process and they’re using an application service account to connect to the database instead of their named account, now they’re basically eliminating any visibility into who that user is by borrowing another account. A lot of times organizations are basically blind to this type of behavior because the DBA has access to everything. It’s an area where security doesn’t necessarily understand what’s going on, what should be going on, and in general no alarm bells are going to be going off for compromised detection when it’s careless behavior.
- Similarly, for malicious users, these are users that have legitimate credentials, they’re able to log in to do their job, but maybe they’re being extorted. Maybe they’re taking information to their next job. Ponemon reports 69% of exiting employees admit to taking data with them. It’s not necessarily someone that’s an Edward Snowden, but maybe someone who’s just taking data with them to their next job because they think they’re entitled to it.
When we look at these last two categories [careless and malicious], I think this is an area for improvement within the security industry, and something that’s going to require looking at new technology and new approaches to solve all three use cases, not just the compromised threat profile.
Why is Detection so Difficult?
So why is detection so difficult…why haven’t we solved this problem? Why do we continue to see these very, very large breaches…60, 80, 100 million records at a time? That’s coming from a database, by the way, not from a spreadsheet on someone’s laptop that got left at an airport. That’s coming from a huge data repository within the enterprise.
- Part of the problem is these users have legitimate access. They’re on the network, they work there. When we look at this, it’s not necessarily about IAM [identify and access management], it’s not about access control. Really what it’s about is post-log in detection. I need to see what the user did after they logged in, and is that behavior normal or not. That’s one of the biggest challenges, understanding good versus bad behavior. We’re looking at millions and millions of transactions against a database or a big data environment. How do you determine the good versus bad?
- So what are some of the approaches people are taking? Today, in some cases they’re sending the information to the SOC. Maybe through route logs that they’re writing correlation rules against. Maybe they have other security layers within the environment that they’re trying to piece together to understand this picture. But in most cases they don’t have a very good picture of this post-log in behavior to be able to understand good versus bad, and the result is alert overload. In the case of [the Target breach], they had information sent to their SIEM, within the SOC environment, but they weren’t able to find it. They weren’t able to get to the actionable data.
- The last problem, and I think this is one of the biggest ones, is these large enterprises have dozens or hundreds or thousands of applications within the environment, and they’re all serving different business units and business requirements. You’ve got one team, the security team, that’s responsible for deciphering all this good versus bad, and users and applications and others within the organization accessing data, and so this lack of context is really something that is not going to be solved through predictive static policies, or through just communicating with the business units. You really have to have something more advanced to be able to understand the good versus bad, to be able to sort through the alerts, and be able to provide some context to that team so they can actually go quarantine, follow up and deal with an insider threat once it’s detected.
Identifying Breaches Requires Understanding of Users and Data
We talked about user profiles, let’s next talk about data. And I think what this comes down to is when we’re looking at the challenges of detecting insider threats, it’s really at the intersection of users and data. This is essentially where the data breaches are happening when we talk about insider threats. The Verizon Data Breach Investigations Report that comes out every year has indicated that in a lot of the cases where we see very, very large amounts of data through the forensics and the analysis, it was an insider, someone already within the organization—again, a compromised, careless or malicious user.
Data and User Attributes
When we start talking about big data, databases, file systems, especially databases, there’s a lot more here than just the IP address and the user name. We want to understand more about that user, where they came from, what type of application they were using, which department they’re part of, really the context of that user as they’re interacting with data. When we start getting into some of these other things—the database table, the schema, the SQL operation that was performing against that database, for example—we start to get further and further away from the comfort zone of the security team that’s responsible for protecting this data.
Again, this is where we have that issue with context. It’s not only do we have hundreds or thousands of applications, but now we’ve got sort of a different language that’s not very familiar or comfortable for this security team. We start looking at this amount of data, the key thing is really the type of data, this deep understanding that we need to be able to fill in and address some of these challenges that we talked about earlier.
Machine Learning is Not Magic
What is everyone doing within the industry? If you’ve been to the RSA Conference, if you’ve been to any security show recently or talked to a vendor, chances are they’re telling you about machine learning, and how machine learning or user behavioral analytics (UBA) is going to help solve this problem. In some cases, in very narrow-focused use cases, it’s doing a great job and is really bringing security to the next level. But the key thing to note is that machine learning is not magic. There’s no magic potion where we can just apply machine learning or artificial intelligence against the data set and expect to get good results. You’ve got to start with a very laser-like focus of which problems you’re trying to solve. That really leads us to the next section here, which is key indicators of abuse.
Key Indicators of Abuse
One of the things that we’ve done here at Imperva is really taken a laser-like approach to identify things like service account abuse and machine takeover, excessive database or file access, and done that in the context of a deep understanding of how users interact with data. This is really the key to getting some value out of machine learning, but also solving this insider threat profile problem, having a deep understanding of this intersection between users and data.
Insider Threats: Factor in the Unknown
We’ve talked about machine learning and user behavioral analytics, and I briefly mentioned predefined static policies in an earlier part of the talk. The challenge with this approach, even if I’ve got a very granular ability to set policies to do real time alerting and blocking, is factoring in the unknown. If we go back and look at the previous approach to insider threats, it was mainly about compliance. For example, PCI and compliance had a very tight, narrow scope in what they were looking for, and in fact, the environment was usually very controlled and often times set aside from the rest of the environment. As we start to look at insider threats across the broader environment, across the broader data set, think of Europe’s GDPR where we’re looking for personally identifiable information (PII), which could be all over the enterprise. The problem now is much more challenging. We have to think about, and anticipate, every single mutation of a policy and every variation of how that policy would need to be created. The challenge here is now you’re creating hundreds or thousands of policies, you’re having to maintain those, and behind that, or underneath it the application environment’s changing constantly. It becomes an operational challenge for an organization to sustain.
Static Policies Don’t Scale
The other issue is a lot of times the insider threats are unanticipated. We’re not thinking about all the potential variables of a policy that would need to be created in order to find it. When we look at the database example, and why static policies don’t scale, we have to understand who’s connecting to the database, how do they connect? Are they using SQL*Plus, Toad, Aqua Data Studio, some other type of tool to connect to the database? What data are they accessing? Have I done data classification before? Do I even know the context of that data to be able to write a policy against it? What do their peers do? Is this person doing something that no one else within the DBA group, or no one else within the IT group—or finance, or whatever that group is—is that something that we can use as part of the correlation? How much data do they normally query? Unless I have a baseline and a deep understanding of SQL, first of all, to understand what the amount of data is, or what a query is, or how many rows are coming back from a database, this is something that can be difficult to quantify.
When do they normally work? That seems like a pretty basic one, but if I look at what I need to do to detect insider threats, I need to be able to correlate across these five examples, these six examples [ Who is connecting to database? How do they connect? What data are they accessing? Do their peers access the same? How much data do they query? When do they usually work?] as well as many others, and then all the possible mutations of that. It becomes a real challenge, and as we get into the next section, we’re going to be talking about machine learning, very focused machine learning, so that I don’t have to worry about setting and maintaining hundreds or thousands of predictive static policies over time.

Click to enlarge image.
Detect Insider Threats with Imperva CounterBreach
I talked about the intersection of users and data, and having a deep understanding of those users interacting with data to solve this problem. What CounterBreach does is it essentially uses machine learning to automate the understanding of all of the different variables, both the user variables and data variable in such a way that we can make sense of all this and address the context issue, address the false positives, address not having to create static predefined policies issue.
- One of the first things we do is identify user and connection types. What does that mean? In the database world, one of the biggest challenges our customers have is just differentiating application service accounts connecting to the database, versus interactive users or privilege users like DBAs connect to the database, because they perform and have different responsibilities. If we understand the different users and some organizations, that’s a huge win. I worked with a large payment processing company that literally had a rat’s nest of legacy connections through the database. They didn’t know who was what, and just by going in and automatically differentiating based on behavioral statistics and algorithms…this connection is an application based on velocity, based on what it does, how it connects to the database…we can automatically detect and say, “Hey, this is a service account.” Based on the differentiation, we can also say this is a DBA that’s connecting to the database.
- Once we’ve understood the connection types, and often times that’s a huge win for the organization, the second thing we want to understand is what is the typical purpose of the account in terms of how it accesses data? We see an application account, we’ve profiled that, we understand it’s an application account, we’re going to see it access sensitive data applications. Typically it’s acting on behalf of users, let’s say, on a healthcare portal that are interacting with the application and updating sensitive PII information. We’re going to see certain database operations, certain SQL calls. We’ll get certain tables within the database and be able to classify that at a granular level. When we talk about a deep understanding of data, that’s what I’m talking about—not just the connection but the operations, basically the SQL operations that are being performed against which data. So this is dynamic data classification.
- By the same token we see DBAs also interacting with the database. They need to maintain, again, the performance, uptime and availability, and what we typically see is they’re accessing meta data. I shouldn’t see the same operations against the same tables that the application is doing from a DBA user. One of the common things that we see with CounterBreach is a DBA now that’s normally accessing this data that we’ve seen over a period of time—and built that profile, that good behavior profile—all of a sudden accessing sensitive data because we’ve profiled that this is sensitive data from the application.
Hope you enjoyed the session. I hope it was useful, and join us next time for Whiteboard Wednesday.
Read more about insider threat prevention.
Try Imperva for Free
Protect your business for 30 days on Imperva.





