Organizations in the financial services sector are high-value targets for cybercriminals. In recent years, more sophisticated botnets and other bad bot attack methods have enabled malicious hackers to ratchet up the speed of attacks on this sector. The four most common ways hackers deploy botnets is for credit card fraud, account takeover (ATO) attacks, distributed denial of service (DDoS) attacks, and scraping content from financial services websites. Each of these attack methods results in very specific consequences for the affected organization.
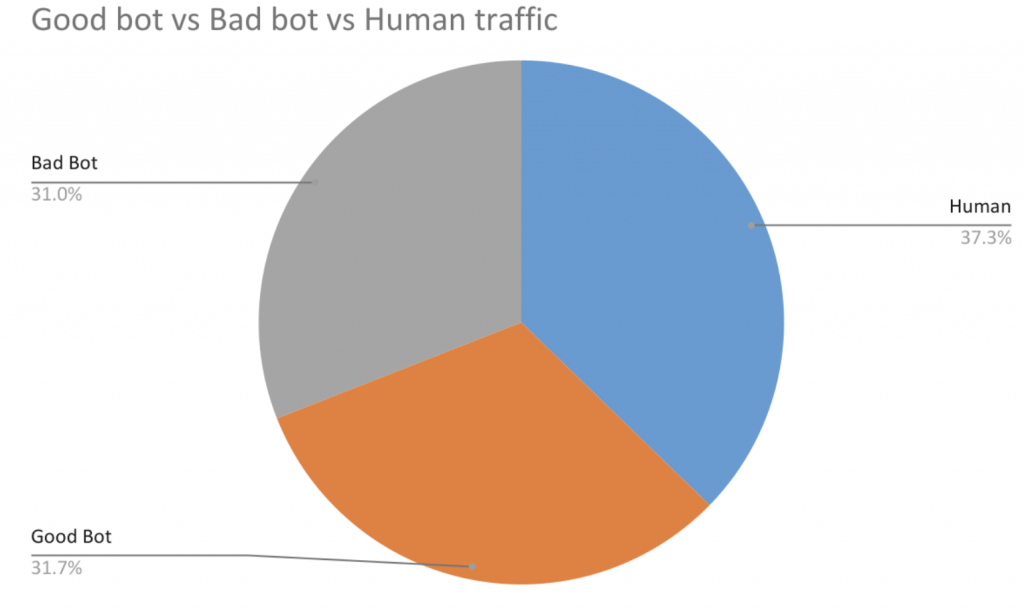
The Imperva Bad Bot Report 2021 lists financial services among the top five industries targeted by sophisticated bad bot traffic. Bad bots are software applications that run automated tasks with malicious intent over the internet and the worst bots undertake criminal activities, such as fraud and outright theft. They enable high-speed abuse, misuse, and attacks on your websites, mobile apps, and APIs. Bots that closely mimic human behavior and are harder to detect and stop. Since the beginning of 2021, only 37% of financial services site traffic is human and around one-third (31%) of all traffic to financial services sites has been made up of bad bots.
In this post, we will take a closer look at four bad bot attack methods that today’s cybercriminals commonly use against financial services organizations. We’ll also give you some ideas about how to prevent bad bots from negatively impacting your organization.
Credit card fraud
What is it
The bad bot-leveraging credit card fraud technique most commonly used by hackers is card cracking. Cracking is based on the idea that it is easy to obtain a credit card number, known as a Private Account Number (PAN), together with the name printed on the card. Attackers use bots to guess and confirm the additional information required to “crack” and illicitly use a credit card. There are several ways criminals can obtain PANs: Buying lists of PANs on the dark web, through accomplices working in retail or restaurants who are exposed to credit card information, adding a device to a credit card swiper that enables unauthorized parties to read the card information and PIN (also known as skimming), and by phishing scams, which typically involve calling the credit card owner and pretending to be an authorized party requesting their credit card details.
In a large-scale operation, the typical attackers’ strategy is:
- Obtain a list of PANs.
- Set up a bot that can attempt small purchases on a large list of payment sites. The bot should attempt a purchase on a website, submitting credit card information for a PAN, and each time guessing a different combination of CVV, expiration and postal code.
- Deploy the bot to operate on 30 payment sites in parallel, to avoid guessing limits.
This procedure would allow an attacker to crack a card every four seconds, and scale up the process to crack as many as 21,600 stolen credit cards per day.
How to prevent it
Device fingerprinting
Fingerprinting combines the user’s browser and device to understand who or what is connecting to the service. Bad bots attempting credit card fraud must make multiple attempts, and cannot change their device every time. They must switch browsers, clear their cache, use private or incognito mode, use virtual machines or device emulators, or use advanced fraud tools like FraudFox or MultiLogin. Device fingerprinting can help identify browser and device parameters that remain the same between sessions, indicating the same entity is connecting again and again. Fingerprinting technologies can create a unique device, browser and cookie identifier, which, if shared by multiple logins, raises a suspicion that all those logins are part of a fraud attempt.
Browser validation
Some malicious bots pretend to run a specific browser, and then cycle through user agents to avoid being detected. Browser validation ensures each user browser is what it claims to be – that it has the expected JavaScript agent, is making calls in a way to be expected from that browser, and is operating in a way that is expected from human users.
Machine learning behavior analysis
Real users visiting payment websites exhibit typical behavior patterns. Bots will typically behave very differently from this pattern, but in ways you cannot always define or identify in advance. You can use behavioral analysis technology to analyze user behavior and detect anomalies – users or specific transactions that are anomalous or suspicious. This can help identify bad bots and prevent cracking attempts. As part of behavioral analysis, try to analyze as much data as possible, including URLs accessed, site engagement metrics, mouse movements, and mobile swipe behavior.
Reputation analysis
There are many known software bots with predictable technical and behavioral patterns or originating IPs. Having access to a database of known bot patterns can help you identify bots accessing your website. Traffic that may appear at first glance to be a real user can be easily identified by cross-referencing it with known fingerprints of bad bots.
Progressive challenges
When your systems suspect a user is a bot, you should have a progressive mechanism for “challenging” the user to test if they are a bot or not. Progressive testing means that you try the least intrusive method first, to minimize disruption to real users. Here are several challenges you can use:
Cookie challenge – transparent to a real user
JavaScript challenge – slightly slows down user experience
CAPTCHA – most intrusive
Other measures to strengthen your security perimeter against cracking bots include:
Multi-factor authentication
eCommerce sites can require users to sign in with something they know (for example, a password) and something they have (for example, a mobile phone). While this does not prevent cracking, it makes it more difficult for criminals to create large numbers of fake accounts, and renders it almost impossible for them to take over existing accounts.
API security
eCommerce sites often use credit card APIs, such as those offered by PayPal or Square, to facilitate transactions. These APIs can be vulnerable to attacks, such as JavaScript injection or the rerouting of data, if not incorporated with the appropriate security. To protect against many of these attacks, eCommerce sites can use a combination of Transport Layer Security (TLS) encryption and strong authentication and authorization mechanisms, like those offered by OAuth and OpenID.
Account takeover (ATO) attacks
What is it
ATO attacks a.k.a. credential stuffing is a method in which attackers use lists of compromised user credentials to breach a system. The attack uses bots for automation and scale and is based on the assumption that many people reuse usernames and passwords across multiple services. Statistics show that about 0.1% of breached credentials attempted on another service will result in a successful login. Credential stuffing is a rising threat vector for two main reasons:
- Broad availability of massive databases of breach credentials, for example, “Collection #1-5” which made 22 billion username and password combinations openly available in plain text to the hacker community.
- More sophisticated bots that simultaneously attempt several logins, and appear to originate from different IP addresses. These bots can often circumvent simple security measures like banning IP addresses with too many failed logins.
In a large-scale credential stuffing exploit, the attacker:
- Sets up a bot that is able to automatically log into multiple user accounts in parallel, while faking different IP addresses.
- Runs an automated process to check if stolen credentials work on many websites. Running the process in parallel across multiple sites reduces the need to repeatedly log into a single service.
- Monitors for successful logins and obtains personally identifiable information, credit cards or other valuable data from the compromised accounts.
- Retains account information for future use, for example, phishing attacks or other transactions enabled by the compromised service.
How to prevent it
In addition to device fingerprinting, multi-factor authentication, and CAPTCHA you can use:
IP Blacklisting
Attackers will typically have a limited pool of IP addresses, so another effective defense is to block or sandbox IPs that attempt to log into multiple accounts. You can monitor the last several IPs that were used to log into a specific account and compare them to the suspected bad IP, to reduce false positives.
Rate-Limit Non-Residential Traffic Sources
It is easy to identify traffic originating from Amazon Web Services or other commercial data centers. This traffic is almost certainly bot traffic and should be treated much more carefully than regular user traffic. Apply strict rate limits and block or ban IPs with suspicious behavior.
Block Headless Browsers
Headless browsers such as PhantomJS can be easily identified by the JavaScript calls they use. Block access to headless browsers because they are not legitimate users, and almost certainly indicate suspicious behavior.
Disallow Email Addresses as User IDs
Credential stuffing relies on the reuse of the same usernames or account IDs across services. This is much more likely to happen if the ID is an email address. By preventing users from using their email address as an account ID, you dramatically reduce the chance of them reusing the same user/password pair on another site.

Distributed denial of service (DDoS) attacks
What is it
Hackers frequently deploy a botnet, a group of hijacked internet-connected devices, each injected with malware used to control it from a remote location without the knowledge of the device’s rightful owner to carry out DDoS attacks. Layer 7 (application layer) DDoS attacks target the top layer or the application layer of the OSI model which helps facilitate connections over internet protocol. The aim is to overwhelm server resources by flooding a server with so much traffic in the form of requests to connect until it is no longer capable of responding. The higher the number of requests per second (RPS) the more intense the attack.
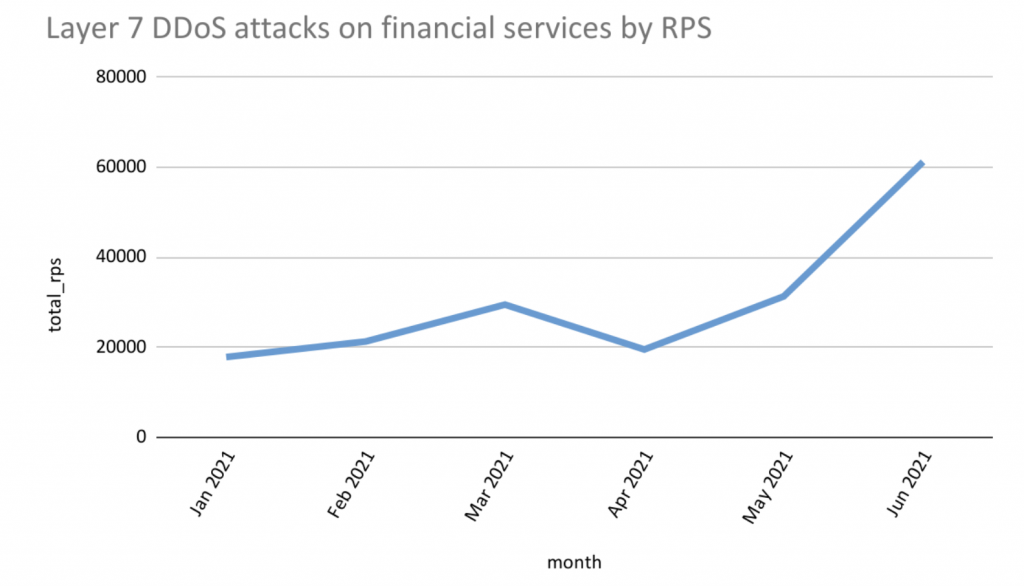
Data monitored by Imperva Research Labs shows the number of requests per second (RPS) in Layer 7 DDoS attacks against financial services targets has significantly increased since April 2021. This is in line with the CTI risk score which also shows a surge in the threat risk from April.
How to prevent it
Imperva provides easy to use, cost-effective and comprehensive DDoS protection that pushes the envelope for cloud-based mitigation technology.
Through a combination of on-demand and always-on solutions, a global network that offers near-limitless scalability and filtering solutions for transparent mitigation, Imperva completely protects customers from DDoS attacks.
Content scraping
What is it
Web scraping is the process of using bots to extract content and data from your website. Unlike screen scraping, which only copies pixels displayed on-screen, web scraping extracts underlying HTML code and, with it, data stored in a database. The scraper can then replicate entire website content elsewhere. This is an issue for financial services organizations because when hackers steal your content (e.g. published loan interest rates, product benefits, etc.) they are a parasite on your efforts. Duplicate content damages your SEO rankings. Tell-tale signs of content scraping are unexplained website slowdowns and downtime can be caused by aggressive scrapers.
There are several key differences to help distinguish between legitimate and malicious content scraping bots. Legitimate bots are identified with the organization for which they scrape. For example, Googlebot identifies itself in its HTTP header as belonging to Google.
Malicious bots, conversely, impersonate legitimate traffic by creating a false HTTP user agent.
Legitimate bots obey a site’s robot.txt file, which lists those pages a bot is permitted to access and those it cannot. On the other hand, malicious scrapers crawl the website regardless of what the site operator has allowed.
How to prevent it
To counter advances made by malicious bot operators, Imperva uses granular traffic analysis. It ensures that all traffic coming to your site, human and bot alike, is completely legitimate. The process involves the cross verification of factors, including:
HTML fingerprint
The filtering process starts with a granular inspection of HTML headers. These can provide clues as to whether a visitor is a human or bot, and malicious or safe. Header signatures are compared against a constantly updated database of over 10 million known variants.
IP reputation
Imperva collects IP data from all attacks against our clients. Visits from IP addresses having a history of being used in assaults are treated with suspicion and are more likely to be scrutinized further.
Behavior analysis
Tracking the ways visitors interact with a website can reveal abnormal behavioral patterns, such as a suspiciously aggressive rate of requests and illogical browsing patterns. This helps identify bots that pose as human visitors.
Progressive challenges
Imperva uses a set of challenges, including cookie support and JavaScript execution, to filter out bots and minimize false positives. As a last resort, a CAPTCHA challenge can weed out bots attempting to pass themselves off as humans.
Try Imperva for Free
Protect your business for 30 days on Imperva.